Introduction
The Egyptian_Pre-Coptic treebank (EPC) is the first linguistic corpus for the morphosyntactic annotation of Pre-Coptic Egyptian texts. It was created in March 2024 in Universal Dependencies (UD) and was first published in the May 2024 edition of UD (2.14), which contained 5,515 tokens and 707 sentences. The EPC morphosyntactic treebank now consists of 34,234 tokens and 3,089 sentences in the May 2026 edition of UD (2.18). All of these sentences are taken from the Pyramid Texts — a collection of utterances recited during the funeral rites of Old Kingdom kings and queens (c. 2543–2120 BC).
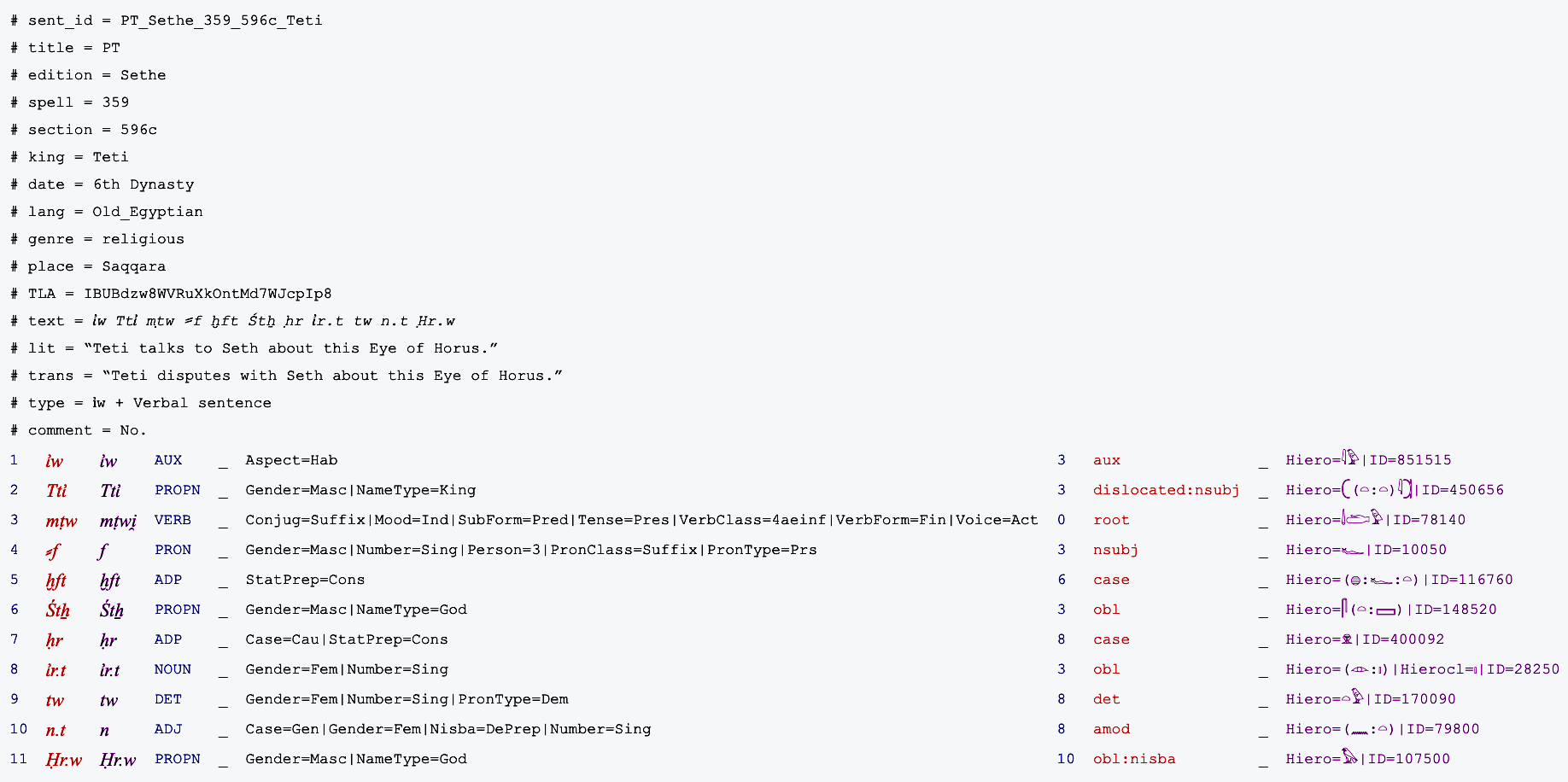
The EPC treebank aims to annotate the morphological features and syntactic relations of the most representative texts from Old and Middle Egyptian, Classical Egyptian, Late Egyptian, and Demotic (see Díaz Hernández, Passarotti: 2024). The sentences analysed in the EPC morphosyntactic corpus consist of sixteen metadata sections: sent_id, title, edition, spell, section, king, date, language, genre, place, TLA, text, literary form, translation, type and comment. The EPC morphosyntactic corpus is published without the 'lit', 'trans', 'type' and 'comment' sections, as these require further review prior to publication. Words in each sentence are analysed across ten columns, following the Universal Dependencies approach:
Column 1: Word index, i.e. position of the word in the sentence.
Column 2: Word form.
Column 3: Lemma.
Column 4: Universal part-of-speech tag.
Column 5: Language-specific part-of-speech.
Column 6: Morphological features.
Column 7: Head of the current word.
Column 8: Dependency relation.
Column 9: Enhanced dependency graph.
Column 10: Hieroglyphs, classifiers and word IDs.
Columns 5 and 9 are not recorded as they are irrelevant to the EPC morphosyntactic database.
The UD section on Egyptian, which I drafted in April 2024, outlines how the UD approach is used to annotate Egyptian texts. Prior to the creation of the EPC treebank, there was no digital tool available for the study of Pre-Coptic Egyptian morphosyntax. The EPC treebank has a wide range of applications in computational linguistics, and it has so far been used for the creation or development of the following natural language processing tools:
1) GrewPT, a web application for the analysis of the Egyptian language and script of the Pyramid Texts.
2) The EPC Parser, which is used to automatically parse Egyptian sentences. It offers the possibility of creating morphosyntactic tree diagrams for educational and research purposes.
3) The PARSEME repository of Egyptian multi-word expressions. This repository has been developed by the PARSEME Egyptian research group at the University of Jaén.
4) The ORAEC meta search engine.
The EPC treebank is also used as a linguistic resource for Egyptian on internationally renowned computational linguistics websites such as TüNDRA and UDPipe.
The EPC treebank is the result of the UniDive COST Action (CA21167), which is funded by COST (European Cooperation in Science and Technology) from 2022 to 2026. I would like to thank Daniel Zeman, Bruno Guillaume and Marco Passarotti for their support in developing the EPC treebank.
For questions and queries, please contact Roberto A. Díaz Hernández, Junior Lecturer in Ancient History, Faculty of Humanities, University of Jaén (radiaz@ujaen.es)